This post will briefly discuss H12 errors on Heroku, more commonly known as request timeouts, how we tackled them, and how we fixed them.
Before we start, let’s establish some context. We have an app that’s a hub for ~600 servers. A few times per day, each server creates a request to the app, ensuring everything is in sync. As we started to add more and more servers, we saw more H12 errors on Heroku. We quickly realized that the problem is that, basically, our servers are DDoSing the app every time they make those requests. Because those requests come from a scheduled cronjob, they all come at approximately the same time.
The quick fix would be to look into those requests and optimize them. But we wanted our app to handle that kind of a load, so we decided to look into HTTP server options. We were confident that we didn’t optimize gunicorn (our HTTP server) enough, so we should start there. Gunicorn async option sounded very attractive because usually async works well with network IO.
Before we started playing around with gunicorn settings, we had to create a simulation that would be our base point. We deployed the app locally and simulated the requests with hey. To be exact, we first spent a day or two deciding which tool to use and learning about different kinds of tests, but I’ll skip this part.
We started hitting our testing app with hey -n 100 -c 3 and slowly brought up the values until we saw some noticeable delays in the response time. The sweet spot was hey -n 300 -c 9. These were the results:
Summary:
Total: 155.1276 secs
Slowest: 8.2932 secs
Fastest: 3.8140 secs
Average: 4.6419 secs
Requests/sec: 1.9146
Latency distribution:
10% in 4.3740 secs
25% in 4.4296 secs
50% in 4.4857 secs
75% in 4.5829 secs
90% in 5.5073 secs
95% in 5.8172 secs
99% in 8.1313 secsWe were running 3 workers, and each consumes ~135 MB. When we started testing, it went up to ~160 MB. Memory usage was measured with macOS activity monitor. We decided to use 3 workers because we’ve gathered from multiple online sources that the number of workers is ( 2 * CPU ) + 1. And because we are running our app on Heroku 2x that is effectively 3 (Heroku Dyno Sizes).
Now that we knew what our baseline was, we could start playing around with gunicorn settings. First, we added some threads (--threads 3) and hit the app with the same hey load.
These were the results:
Summary:
Total: 129.9978 secs
Slowest: 5.6160 secs
Fastest: 1.7642 secs
Average: 3.4477 secs
Requests/sec: 2.2847
Latency distribution:
10% in 2.3322 secs
25% in 2.6989 secs
50% in 3.1087 secs
75% in 4.3065 secs
90% in 4.8934 secs
95% in 5.1969 secs
99% in 5.4308 secsWe saw an increase in speed by roughly 16%. With 3 workers and 3 threads, the memory consumption was 168 MB per worker, and it increased to 174 MB when running the load tests.
This was a very nice increase for such a simple change. We do use a bit more memory, but I would say it’s worth it.
The second experiment was to configure gunicorn with async workers. As mentioned earlier, we hoped that this would be the game-changer. We were hoping to see at least 2x increase in speed. We installed all the required packages and started the server with --worker-class gevent option.
Again we hit the testing server with hey -n 300 -c 9, but something unexpected happened. hey process seemed to crash. Or at least that’s how it looked like. After ~8 minutes, we stopped the testing, and these were the results:
Summary:
Total: 506.0369 secs
Slowest: 19.8003 secs
Fastest: 1.6260 secs
Average: 2.7787 secs
Requests/sec: 0.5316
Latency distribution:
10% in 1.6578 secs
25% in 1.6905 secs
50% in 1.7404 secs
75% in 1.9863 secs
90% in 5.0394 secs
95% in 14.8791 secs
99% in 19.8003 secs
Status code distribution:
[200] 107 responses
Error distribution:
[162] Get "http://localhost:8080/foo/224168/": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
To make things even worse, we saw that memory consumption skyrocketed to a whopping 1,4 GB of memory. What happened here was that gunicorn spawned a bunch of coroutines (async tasks). Probably around 300 (1 per request) because it could easily handle them (that’s how async works). But then all those tasks were stuck while waiting for the database to return the results.
We remembered that we don’t have DB pooling enabled, so we run the same tests with DB pooling, but the results weren’t much better. We even reduced the --worker-connections (maximum number of simultaneous clients), but it didn’t help.
At this point, we realized that the most significant bottleneck is not the HTTP server but the database.
We shifted our focus from gunicorn settings to the code. Specifically to the part where we make database queries. In our controllers, we (almost) never use custom queries like select.query.filter(...) because it’s a dangerous thing to do. One can quickly send too much information to the template, leading to a disaster. So whenever we do database queries, we go via model where we check user permissions. There we also decide which attributes are visible on which type of page. E.g., foo.description isn’t needed on some listing page, but it’s needed in the view/edit pages.
You might see where this is going. Because most of our queries were like this, we were loading way too many things from the database. Even the most straightforward queries were relatively slow, especially if the app had many of them to process. We customized a few database queries, and the results were terrific. These were the results with hey -n 10 -c 10:
Before query optimization:
Summary:
Total: 20.0027 secs
Slowest: 18.0754 secs
Fastest: 1.9990 secs
Average: 10.0892 secs
Requests/sec: 0.4999
Latency distribution:
10% in 3.9964 secs
25% in 8.1121 secs
50% in 12.1707 secs
75% in 16.1096 secs
After query optimization:
Summary:
Total: 1.8265 secs
Slowest: 1.8264 secs
Fastest: 0.1984 secs
Average: 1.0111 secs
Requests/sec: 5.4750
Latency distribution:
10% in 0.3748 secs
25% in 0.7372 secs
50% in 1.0978 secs
75% in 1.6500 secs
90% in 1.8264 secsThis is more than a 10x increase in requests/sec! Combining this with our gunicorn thread optimization (which was ~16% increase), we have entirely solved our H12 error problem.
Here are some screenshots that show before and after effects:
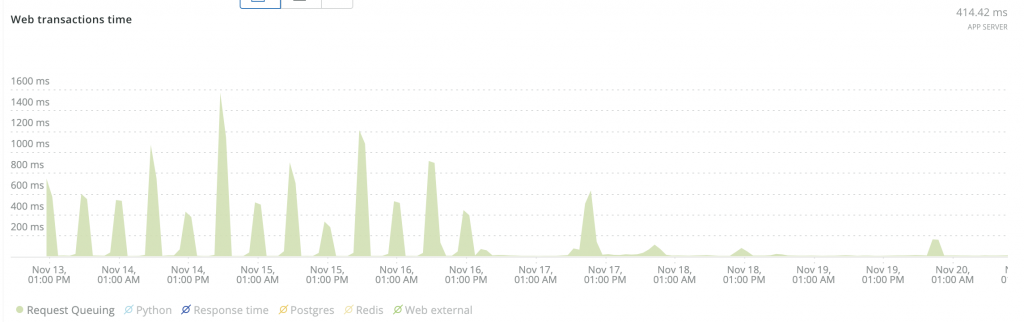
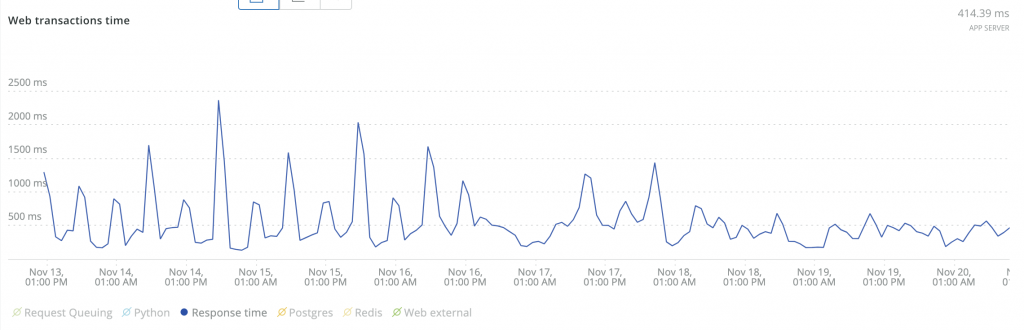
We probably still have some polishing to do, but now we know exactly where to look for it and how to do it.
Summary
I think it’s essential to keep your mind open when you start optimizing your app because the last thing you want to do is to be stuck in a hole, and the only thing you see is to dig deeper (e.g., optimizing HTTP server). It’s important to take a step back, take a pause, and see the big picture. Maybe even take a break and go for a walk and think about the problem.
